When we talk about technical SEO issues, we often focus on the most common factors like page speed, mobile-friendliness, structured data, and some other issues as well.
All of these are incredibly crucial. But most of the time we avoid some other elements, which is as important as these, sometimes even more.
Today we’ll talk about those factors that are boring to work on, but extremely important to do so.
Table of Contents
1. Site Structure 2. Broken Links 3. Non-Crawlable Content 4. Inclusion Ratio 5. Sitemaps 6. Blocked Pages 7. Meta Tags 8. Duplicate Content
1st Chapter
Site Structure
What is site structure? Why is site structure important? Common structural issues How can we assess site structure?
In its purest form, site structure is how you organize your website’s pages, subpages, posts and other elements. The architecture of your site should be in a pyramid structure similar to what we’re seeing here.
Structure is important because the higher a page is in your architecture, the more important it is, but there should always be a logical hierarchy. Otherwise, the search engine has a difficult time identifying your most important pages.
Proper site architecture is extremely vital for both search engines and user experience of your visitors.
It can be difficult to make navigation intuitive, but big sites do a great job with that. If you’re looking for an example, Amazon has each category as a top-level page, so it’s easy to find those product category pages with just one click.
Why Site Structure is Important?
Your most important pages should be easy to find ideally within just a few clicks of the homepage and organized in a very concise and logical way for search engines and users alike.
Architecture helps to show the relationships among content. It indicates that your pages and content are connected in meaningful ways.
Structure’s not only a factor for search bot crawling, but it also establishes the hierarchy of your content. So for search engines, hierarchy = importance.
If you bury important pages deep in your site architecture, you may have limited SEO results, something essential to keep in mind.
As a best practice, You’ll always want to surface and support your core pages through navigation URL structure, breadcrumbs and internal links.
Common Structural Issues
When a crawler comes to your homepage, they look for those internal links and start following those links and crawling additional pages. This is why common structural issues are often link related.
If we’re hiding links, Google or any other crawler may not find them. So if you can avoid pitfalls such as the ones listed here, you can make links easily accessible and findable.
So some common issues are:
links that are only accessible through internal search boxes.
Any links that you might have inside some JavaScript or Flash or any other kind of plug-in.
Pages with hundreds or thousands of links, they may not be hidden, but there’s so many that it makes it difficult for both search engines and users and
Any links buried in i-frames.
Now an evaluation of the structure of the site includes folder structure navigation, internal links, as well as data from Google and any other type of third-party Crawlers.
How Can We Assess Site Structure?
There are a few different ways to do it. But one of the best ways is through the tool Screaming Frog. It’s free and will crawl up to 500 URLs for free. Now if you’d like the tool to crawl more than that, you can pay for additional access, but download their application and use it for up to 500 URLs is free.
Now we’ll open the application and enter a URL such as localseolads.com, which I’ve done here. Then click on the hierarchy icon. What happens is now it shows us the structure and gives a sense of our hierarchy.
In this left-hand column, we’ll see the path. This is our folder structure, and then on the right we’ll see the URL.
2nd Chapter
Broken Links
What is broken or dead links? Why are they bad for SEO? How can we analyze and resollve broken link issues?
Broken links are the links on a web page that don’t work. They’re often the result of a URL change or the relocation of page content on the website.
And when abundant, broken and dead links prevent search engine crawlers from indexing pages. Because if Googlebot only hits broken links on your site and your internal navigation is broken, It could have a problem indexing your pages and ranking your website.
Imagine driving through a neighborhood with a lot of dead ends. It prevents you from finding what you’re looking for. And it’s a waste of time and gas, and you probably won’t come back and drive through that neighborhood too often again.
Why are they bad for SEO?
Broken links signify that you don’t actively optimize your site and if you have a lot of them and you don’t fix them, it could signal to Google that you’re neglecting part or all of your site and maybe even abandoned it.
It potentially hides important content from the crawler. So if there are links to pages that exist behind a 404 page, the crawler will never find those pages.
It’s a waste of the crawler resources and you can lose customers. You can always go back in and resolve 404 errors, but the most important reason for broken links is this last reason – losing customers.
How Can We Analyze Broken Links?
You can find broken links using any of the SEO tools out there, but I’d suggest using Screaming frog. As it’s free and easy to use.
Enter your URL at the top in this application and then under response codes, you’ll click on client error 4XX. And that will show you a list of all of the URLs that are returning the 404 errors.
Once you locate them, you’ll need to decide on a solution and here are just a couple of solutions for individual Pages.
Your first solution is to remove the link or replace it with another live link from the referring URL. That’s a good solution for low traffic low page authority low-quality pages. That won’t cause any decrease in your domain authority and won’t affect your site too much.
The nice thing about removing the link from the referring URL All together is that it completely removes the link from your site, and it won’t cause confusion with your users.
Another solution is to redirect the link by implementing a 301 redirect. Now that’s good for pages that have a high page Authority because it can be useful for your domain authority to redirect those links.
But if you’re going to redirect a user to a new page, it’s got to be relevant. Google’s looking for the relationship between the original link and your final destination and making sure that you’re taking the user to a relevant page for the best user experience.
Lastly, you can leave it as a 404. This is good for any low traffic low page authority pages. It tells the users that the info that they’re expecting to see doesn’t exist.
Just make sure that if you do leave it as a 404 you have a customized page. 404 Pages can be customized to provide a better user experience similar to what we’re seeing here on the screen, with lego.com.
Here are some examples of beautifully designed 404 pages.
3rd Chapter
Non Crawlable Content
In this section, we’re gonna talk about what are some non-crawlable content, does your webpage contains any of those elements, and lastly we’re going to check if your site is being affected becauese of these.
Since 2014 Google has been claiming that, they’re fine with crawling and rendering JavaScript. But despite that claim, there’s been a lot of advice of caution around JavaScript. Sometimes it can be a bit too complex.
JavaScript can cause some challenges. And this has been a hot topic of debate, and it’s something worth considering.
If you’re worried that JavaScript might be an issue, you can disable JavaScript in your browser and take note of any missing elements and make sure that those navigation links still show up and work when you click them.
You can do that in your browser settings. Go to your website and right-click and then select inspect. Click on the Settings icon.
Scroll down to debugger and click on disable JavaScript. Make sure that all of your links are still showing up and make sure they’re still clickable and working. You can use this JS Error Test Tool as well.
If your site uses flash objects, you can also use the flash test on SEO site checkup to gauge your site’s flash performance flash content doesn’t always work well on mobile devices.
It can be challenging for crawlers to interpret, so you may want to test that if you have flash on your site, it’s definitely worth checking.
How to Identify Non-Crawlable Content?
We can use screaming frog. I entered my site Local Seo Lads and clicked start. And then, on the right I’ll click on internal and click on JavaScript. It gives me all of the URLs that contain JavaScript.
If we can identify the pages that contain JavaScript, it doesn’t necessarily mean we need to go in and remove all of it or take JavaScript out of our sight altogether. You can measure, monitor and manage expectations for those pages if you can at least identify the pages that contain JavaScript.
Maybe compare the performance of those pages to some pages on your site that don’t contain JavaScript. See if there’s a difference. That way you can see is Javascript possibly affecting your site’s performance, rankings, et cetera.
4th Chapter
Inclusion Ratio
In this chapter, We’ll talk about:
What is inclusion ratio? How can we determine this? How does it affect our SEO?
In SEO, the inclusion ratio is the difference between what exists on our site and what the search engine thinks exists. We’re looking for a discrepancy here.
And there’s three scenarios of inclusion results.
1. The first one is what might be considered ideal. The number of indexed pages equals the number of actual Pages, or they are roughly equivalent.
2. The second scenario is that the number of indexed pages are higher than the number of actual pages on your website. Now one reason for that scenario could be that there’s duplicate content on our site.
3. The third scenario is that the number of pages that are indexed is less than the actual number of pages on your site, and one reason for that could be that we’re blocking pages.
How to determine the inclusion ratio?
A quick way to find the number of pages that Google is indexing is to do a site command. This way, we can see how many pages have been indexed by Google.
To do this, go to Google type in site:yourdomain.com. So here’s an example using the site ahrefs.com.
I went to Google typed in site:ahrefs.com and then it gives me the search engine results page with the number of results returned by Google up here at the top.
So the first question to ask is how many pages have been indexed by Google?
We can see that in this example, Google has indexed 2270 pages for this site.
Now, does this really represent the number of pages that exists on Ahrefs? Or is this the number of pages that Ahrefs wants to be indexed?
Another way to find the number of pages that Google has indexed is in your Google search console.
If you’re not familiar with Google search console, This is a free tool that helps you monitor and maintain your site’s presence in the Google search results. So you can get a cleaner number and probably more accurate.
You can do that by submitting a site map. In the sitemaps lesson, you’ll learn how to create a sitemap submit it to Google search console.
Here you’ll see the number of pages that have been submitted versus the number of pages that have been indexed. And that’s another way to get your inclusion ratio.
5th Chapter
Sitemap
We already know what sitemap is, in this chapter, we’ll talk about:
How important is a sitemap XML sitemap best practices How to submit & test a sitemap
The first step to getting your site indexed is to be sure that Google can find it. And an excellent way to do that is to submit a sitemap.
It is a file that tells the search engines about new or changed pages on your site.
XML sitemaps indicate to search engine spiders what pages exist on the site.It lists the URLs and some additional metadata about each URL. That metadata includes things like when it was last updated or how often it changes or how important it is. And that way, search engines can more intelligently crawl your site.
Is a sitemap strictly necessary?
No, not technically, your website will still work without one. And it can even be crawled and indexed by search engines. But it is a chance for you to be a bit more proactive about getting crawlers to visit your pages.
So, why do it? Well, the biggest reason that you should create and submit a sitemap is indexing. Even though search engines can still technically find your pages without one adding a sitemap makes it so much easier for them.
You might have orphaned pages, which are pages that got left out of your internal linking or just pages that are hard to find. Sitemaps help search engines crawl these pages more intelligently.
Here’s an example of an XML sitemap on an e-commerce site. The site is called boohoo.com
If we look closer to one of these entries, what we can see is some information. The first one is the location of the page and the last modified date and time here..
You’ll always want to use absolute URLs uniformly in your sitemap. Including the HTTP, www or .html at the end.
XML sitemap best practices
how do we create a sitemap
If you’re using WordPress, some plugins do the work automatically for you. Yoast Seo and Rankmath are two perfect examples.
Another way of doing this is to use the Screaming Frog tool.
So once you’ve downloaded the screaming frog application, you can enter a URL into screaming frog. Here’s a quick video that demonstrates the process.
Once you create that sitemap file, you need to place it on your web server. Then you need to inform the search engines, and you can do this by submitting it to Google via your Google search console.
Testing your sitemap
You can check and test your sitemap status in GSC, but you can also do this in Screaming Frog application. Follow these steps:
Click on that mode menu and select the list from the drop-down menu.
Now once you’re in list mode, click on upload button.
Then from that drop-down, click on the download site map.
This is where you’ll enter the URL of your XML sitemap location.
So here we’re going to test the XML sitemap for Local Seo Lads in this quick video.
You can see here how screaming frog pulled all of the URLs listed on that XML sitemap, then crawled.
We see a crawl summary on the right sidebar. This is where we’ll be able to see several technical components such as title tags, meta descriptions, H1 tags, server response codes, etc.
For each of the URLs in that XML sitemap, If you look at that crawl summary, you can get a quick overview of which pages have issues and which ones need to be addressed.
Chapter 6
Blocked Pages
In this chapter we’ll talk about:
What is robots.txt How does this work Example and breakdown of a file Recommended areas to block
When search engines have indexed fewer pages than your actual pages. It could be because you’re blocking the crawler from crawling and indexing pages on your site.
Gap.com is an excellent example of this. On the Gap domain where the index count is less than the actual count.
Let me show you an example. If you go to Google and type in “site:gap.com”, Google will return the approximate number of results that they indexed.
In this example, you can see that Google has indexed approximately 167 thousand pages on the gap.com domain.
Now Gap actually has over two hundred thousand pages on their domain. The reason the index count is less than the actual count is that Gap blocks pages via robots.txt.
Robots.txt
The robots.text is a text file that notifies the search engine as to which pages, files, directories, sub-directories etc that it should and should not crawl and index.
You should be able to find it by typing in the URL of your site and then / robots.txt. And you can actually take a look at any sites robots.txt this way.
So when your site is indexed, you can provide instructions to the crawler with this file. When a search engine comes to your site, the first place they go is the robots.txt file and then your sitemap.
We recommend that you take a look at your website’s robots.txt file and make sure that it follows some best practices. Such as it should be in your top-level directory.
If your site is located at www.domain.com, the robots.txt file should be located at www.domain/robots.txt. You’ll also want to have a separate robots.txt file for each subdomain on your website.
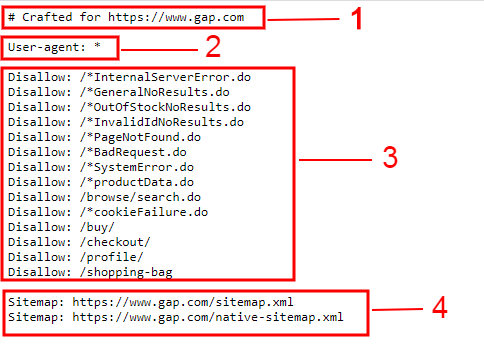
Example of a Robots.txt File
Here we see some instructions in this example of a robots.txt file. Let’s go through them.
1. The first couple lines that we see are starting with a hashtag or pound sign means that these are not instructions for the crawler. These are instructions for humans to read.
These are kind of like notes so that when humans like you and I come to our robots.txt file. Those are for us to read, not instructions for crawlers.
2. Next, we see user agents. This is naming the crawler. So this is saying for this particular crawler, you should follow these instructions.
It might be followed by something like Google bot, which is the name of Google’s crawler. Or Bing Bot, which is the name of Bing’s crawler.
Instead, what we see here is an asterisk or star. An asterisk means wildcard. So it means all crawlers. Any time you see an asterisk, it basically means all. So User-agent: * means that the following instructions are for all crawlers.
3. Allow means yes, crawl. Disallow means do not crawl or index, we don’t want these pages to be crawled.
You should have one disallow line for each URL, folder, or directory that you’re blocking the search engine from accessing.
4. Call out your XML sitemap location. So the last line in many robots.txt files is a directive that specifying the location of the site’s XML sitemap.
Be sure that you’re using your robots.txt file for this so that you don’t miss this opportunity to call out your site’s shape and form and where these essential pages live. So here we see a site map. And then the location of the site map.
Recommended Areas to Block
There are no universal rules for which pages that you should be disallowing. Your robots.txt file will be unique to your site.
You can look at some of the similar sites. Just type in example.com/robots.text to get an idea of what other websites are doing. But you really want to use your best judgment as to which pages or sub-directories of your site should be blocked from search engine crawlers.
These are some examples of recommended areas to block. So anything that’s like users account-related, such as account pages or gift registries or wish lists, Those are popular pages to block. You may want to prevent internal searches that result in almost an infinite number of results or URLs.
Chapter 7
Meta Robots Tag
In this section, We’ll learn how meta robots tag can be used to block pages:
What is meta tags Robots.txt vs Meta tags Different kinds on=f meta tags
The Meta robots tag or meta tags are different from robots.txt file. These are pieces of code that provide the crawlers instructions for how to crawl or index a webpage’s content.
Meta tags allow us to get a bit more granular so that we can noindex a specific page but not necessarily lose out on link authority.
Robots.txt vs Meta Tags
Meta tags aren’t a replacement for the robots.txt file. Robots.txt file controls which pages are accessed, these meta tags control whether a page is indexed. But to even see this page, it needs to be crawled. duitar vs
Whereas robots.txt file gives the bots suggestions for how to crawl a website’s pages, meta tags provide more firm and specific instructions on how to crawl and index a particular page’s content.
If crawling a page is problematic, so for example, if the page causes a high load on the server, then use your robots.txt file. heavy page wall or police kata tar
If it’s only a matter of whether or not a page should be visible in the search results, you can use these robots meta tags. thank you page nise nofollow
This is at a page level setting, and these meta tags should be in the head section of a page.
NOINDEX, NOFOLLOW vs NOINDEX, FOLLOW
Here the first one we see NOINDEX, NOFOLLOW. These directives are for areas of the site that we do not want Google to crawl or index.
So if we don’t want Google to crawl or index a specific page, we can put these directives on that particular page.
NOINDEX, FOLLOW is useful for situations such as pagination, where we want Google to crawl the series, but maybe only index the first page.
Chapter 8
Duplicate Content
In this section, we’ll talk about:
What is duplicate content How do they appear How to resolve them
Duplicate content is when the same piece of content or similar content appears more than once on your website. Duplicate content is a pretty significant issue that is seen throughout websites.
The challenge is that, you can have multiple pages that are either identical to one another or appear to be identical to one another. And when the search engine tries to rank those pages, it may be challenging to decide which one is the appropriate page to rank for a given search query.
Make it easy for the search engine to understand which variant if there are multiple variants is the one that you’d like to have displayed or at least how to get rid of those that you don’t want to have as duplicates.
Here’s a great example. There are many different URLs shown on this example, and all of them are technically for the same page. Yet they all would be seen by the search engine as independent of one another.
Some of the common things that we see are related to security certification. Whether or not it’s an HTTP versus an HTTPS. And whether or not you have a www versus a non-www version of your site.
How They Appear & How To Resolve Them
There’re tons of ways duplicate contents can take place on a website. Here are a few of them:
There are many ways to resolve them as well. Let’s look at some:
THE END!
So these are the most crucial 8 technical SEO factors that you want to resolve for your website. If you face any problems in any of these steps feel free to reach me. I’d be happy to help!





































")




